
In this edition of "Digital Discourse," we are honored to invite Mr. Wang Feng, an expert in the field of data quality evaluation. Mr. Wang is the Head of the Blockchain and Data Services Department, Director of the Data Intelligence Innovation Studio at the China Quality Certification Centre (CQC), an Industry Professor, and a member expert of the Jiangsu Provincial Digital Economy Society. His research focuses on various areas, including data product quality, high-quality datasets, data annotation quality, data security compliance, trusted data spaces, data asset valuation and capitalization, as well as testing and certification. He is dedicated to advancing digital certification and full-element data services.
Q1: As an expert in data quality evaluation, could you please explain to our readers what a "high-quality dataset" is? Compared to traditional datasets, what are its core characteristics and evaluation criteria?
A1: Wang Feng
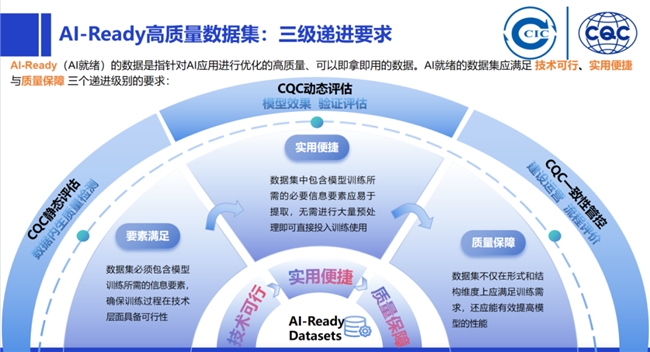
—— High-quality datasets specifically refer to a type of data product serving artificial intelligence. They possess characteristics such as freshness, authenticity, large sample size, completeness, diversity, and high knowledge density, and must meet three progressive requirements: technical feasibility, practical convenience, and quality assurance.
(I) Definitions of Data and Related Terms
1. Data: According to Article 3 of the "Data Security Law," data refers to any record of information in electronic or other forms. For example, a recording of an online conversation records information electronically and is data; taking notes in a notebook records information by other means and is also data. Therefore, data has multiple forms of expression and can be categorized from different dimensions.
2. Dataset: A dataset is essentially a collection of data. These data points are gathered together in a specific organizational manner for storage, management, analysis, and application.
3. Data Resources: When data accumulates to a certain scale, beyond its original function of recording information, it gains the potential for further mining to uncover higher value. At this point, it becomes a data resource.
4. Data Product: A dataset that is treated as a product is a data product. It is an information service derived from a dataset. Currently, numerous data products are listed for trading in national data exchanges (on-exchange trading), with each exchange housing several thousand.
-
Data Asset: There are three core defining elements: first, it is legally owned or controlled by an entity; second, it can be measured in monetary terms; third, it can bring direct or indirect economic benefits. A data resource meeting these three core elements is a data asset.
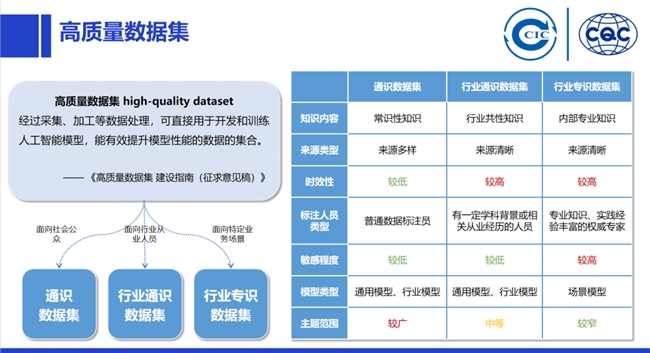
(II) Definition and Characteristics of High-Quality Datasets
1. Definition: Its essence is a type of data product. Director Liu Liehong of the National Data Administration proposed that "datasets meeting the three progressive requirements of technical feasibility, practical convenience, and quality assurance, and reaching the 'quality assurance' level of AI readiness, can be called high-quality datasets." The "Guidelines for Building High-Quality Datasets" (Draft for Comments, National Standard) defines them as collections of data that, after processing such as collection and refinement, can be directly used to develop and train AI models, effectively enhancing model performance. Synthesizing these views, high-quality datasets have a preset scenario, specifically serving AI applications. It does not merely refer to datasets possessing high-quality characteristics like completeness, consistency, and timeliness in a general sense, but specifically denotes datasets serving AI scenarios.
-
Characteristics Compared to Traditional Datasets: They exhibit characteristics such as freshness, authenticity, large sample size, completeness, diversity, and high knowledge density. They must satisfy the three progressive requirements of technical feasibility, practical convenience, and quality assurance.
Q2: You mentioned in the article that CQC issued the nation's first certificate for an AI high-quality dataset. Could you elaborate on this specific case, detailing the key technical methods used in the evaluation process to ensure dataset quality? How do these technologies address practical issues like data rights control and quality auditing?
A2: Wang Feng
—— Looking back, we have been engaged in this work for several years.
At the 2022 World Artificial Intelligence Conference – Forum on Frontier Exploration of Data Element Circulation Technology, we issued the nation's first Data Product Quality Evaluation Certificate to ICBC Technology (Beijing) Co., Ltd., a subsidiary of the Industrial and Commercial Bank of China. This filled a gap in third-party certification services within the data element circulation field and established a practical model for the data element circulation market. In 2023, we issued the nation's first Data Product Quality Evaluation Certificate for the electric power industry and, together with appraisal agencies, released a data asset valuation report. This pioneering practice case involved assessment based on market reference prices provided by data exchanges, combining the fair value of the market approach with the cost approach.

With the advancement of AI, we actively responded to the national "AI+" action by initiating research and development for evaluations related to AI high-quality datasets. To date, we have issued certificates up to the fourth batch, with an overall pass rate of about 30%. Relevant news has been published online. For instance, the first AI high-quality dataset certificate was awarded to a Jiangsu-based enterprise – Shuzu Technology (a member unit of the Jiangsu Provincial Digital Economy Society) – for its dataset on enterprise operational indicator characteristics.

A brief introduction to Shuzu Technology's dataset situation:
Typicality and Characteristics: This dataset is highly representative, comprehensively covering static evaluation, dynamic evaluation, and consistency control. It includes two data modalities: text and image. It covers dimensions of enterprise operational data, such as industry and commerce, judicial, intellectual property, invoicing, and taxation, reflecting various enterprise operational indicator characteristics and boasting wide application scenarios. We advocate for designing and constructing datasets for specific scenarios, and this dataset embodies that philosophy perfectly.
Scale and Characteristic Embodiment: Among the evaluated datasets, the cleaned text data amounts to 12 Terabytes (TB) , and the cleaned image data scale reaches 18 TB. The large data volume provides the large sample size characteristic, while also possessing the high knowledge density feature. Furthermore, evaluations were conducted across numerous indicators such as diversity, completeness, cleanliness, consistency, density, balance, originality, and security (with secondary and tertiary indicators under these main ones). It also met the corresponding requirements during the dynamic model training phase.
—— Currently, we are continuously optimizing the key technologies we employ and delving deeper into frontier exploration.
Enhancement of Tools and Methodologies: From initially issuing certificates for data products to now evaluating high-quality datasets, our tools and methodologies are constantly being summarized and improved. However, this work hasn't been ongoing for long, and many technical challenges still need to be overcome.
Exploration Relying on Trusted Data Spaces: The nation is vigorously promoting the construction of data infrastructure. Currently, there are six main technical routes, the fourth of which is the trusted data space. This year, the National Data Administration released pilot directions for three of the five types of data spaces (Enterprise Trusted Data Space, Industry Trusted Data Space, City Trusted Data Space). We rely on trusted data space infrastructure to conduct credible evaluations within the space, engaging in frontier exploration to solve current problems.
Q3: With the rapid development of AI technology, high-quality datasets have become the cornerstone for refining and innovating AI models. The "Technical Specification for AI High-Quality Dataset Evaluation," which you helped develop, innovatively proposes the "CQC-6D Model" evaluation system. Could you provide an in-depth analysis of this evaluation system? In practical application, which dimension of evaluation have you found to be the most challenging?
A3: Wang Feng
—— The "CQC-6D Evaluation Model" primarily assesses high-quality datasets from six dimensions: Data Description, Data Modality, Data Quality, Model Application, Data Service, and Data Management. It aligns with relevant technical documents from the National Data Standardization Technical Committee and the latest technical standard dynamics, and also meets the three progressive requirements mentioned by Director Liu of the National Data Administration.
The "CQC-6D Evaluation Model" considers the following dimensions:
First is the intrinsic quality requirement of the dataset itself: This involves data indicators such as completeness, diversity, density, cleanliness, accessibility, and model adaptability. Second is dynamic evaluation: Given that high-quality datasets serve to enhance models, this dimension focuses on their enabling performance on related AI models. Third is quality consistency control: Taking mineral water production as an analogy, it's necessary not only to ensure that sampled bottles meet market standards for circulation but also to guarantee that every bottle produced on the entire production line meets requirements. The same principle applies to high-quality datasets.
The "CQC-6D Evaluation Model" is further broken down into the following six secondary indicators, reflecting the static, dynamic, and consistency control mentioned above from different perspectives:
Data Description primarily serves the selection of training datasets, encompassing basic dataset information, content characteristics, construction process, and application descriptions – essentially evaluating the completeness of documentation for different aspects of the data.
Data Modality: Taking the high-quality dataset we evaluated and certified as an example, it includes two modalities: text and image. In reality, there are many other modalities, such as video, audio, 3D point clouds, time series, chain-of-thought, and large model dialogues.
Data Quality Indicators include characteristic indicators related to model properties, covering both data quality and model application metrics.
Data Service and Data Management dimensions indirectly verify the capability requirements for consistency control.

—— From a practical application perspective, the entire industry currently faces several common challenges. Among them, the most challenging dimensions are the lack of evaluation standards for industry-specific datasets and the foundational work required for dynamic model validation.
First, the evaluation of multimodal data. Second, the evaluation of datasets for different industries. The main difficulty here is the current lack of corresponding standards. However, encouragingly, this year the National Data Standardization Technical Committee has been actively organizing, holding two Data Standards Week events – once in Chengdu in the first half of the year and again in Nanjing from November 3rd to 7th. In the second batch of pre-research data standard projects, 49 standards and 26 technical documents are currently underway. Working groups are focusing on standards related to AI high-quality datasets, covering aspects like construction guidelines, technical requirements for data synthesis, requirements for data quality evaluation systems, maturity model requirements for construction and operation, and embodied AI data annotation. Moreover, standards for different industries such as petrochemicals, wind power, thermal power, coal, mining, and media are also being drafted intensively. It is foreseeable that as the industry collaborates in areas like standard setting and scenario expansion, these difficulties will gradually be resolved. Third, regarding the enhancement of dynamic benchmarks and dynamic validation for models, there is still considerable foundational work to be done. This process goes hand-in-hand with industrial development, requiring significant effort and collective action from everyone.

Q4: In your view, how should an average enterprise go about building a high-quality dataset system suitable for its own business needs from scratch? Could you share some practical operational experiences?
A4: Wang Feng
—— Not every enterprise necessarily needs to build a high-quality dataset. For ordinary enterprises that do have such a need, it is advisable to first refer to relevant national standards and complete the following foundational work before embarking on data and related business exploration.
First, sort out the data resource catalog and carry out data classification and grading. In 2024, the nation released the standard GB/T 43697-2024, "Data Security Technology – Rules for Data Classification and Grading" (a recommended national standard). Enterprises can start from here. Second, focus on valuable scenarios within the industry chain to productize data and list data resources on the balance sheet. The Ministry of Finance issued the "Interim Provisions on Accounting Treatment for Enterprise Data Resources" in 2024, adding a "data resources" entry to the balance sheet. Many enterprises value this work of capitalizing data resources and promote it from a strategic perspective. This not only measures an enterprise's digitalization level but also serves as a touchstone for its digital transformation. Many enterprises are capable of undertaking these tasks.
—— For enterprises oriented towards intelligent transformation, possessing high knowledge density, large data volumes, and high-value data, creating a high-quality dataset is feasible, but the construction process is challenging. They should first analyze their needs and their position in the industry chain, clarify the scenarios, data scope, and usability, and then leverage appropriate data collection methods to improve the quality of collection and annotation, as well as conversion rates.
1. Data Requirements: Many enterprises want to build high-quality datasets without clearly defining the scenarios – this sequence is actually inappropriate. The priority should be to first identify valuable scenarios within the industry, enterprise, or industry chain. Combine this with the enterprise's own data characteristics to sort out corresponding requirements, clarifying the data scope and content, such as data format characteristics, usability checks, and data quality model construction.
2. Data Planning: This involves a significant amount of work, including constructing data graphs, attribute lists, relationship models, implementation plans, data quality plans, and estimating the required manpower, time, and resources.
3. Data Collection: There are many collection methods available today. Enterprises need to continuously improve their data gathering methods through suitable means to enhance the quality of data collection.
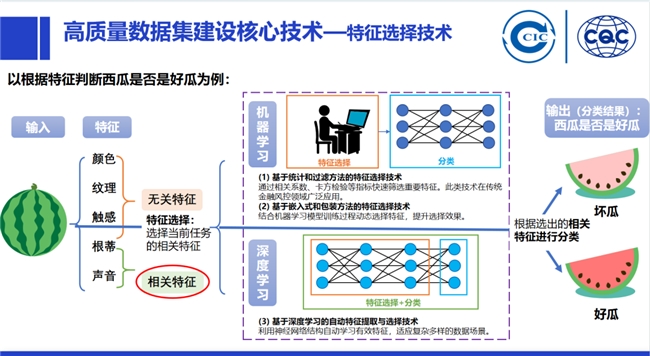
4. Data Preprocessing: There are numerous related technologies in this area. Enterprises must effectively perform data transformation, completing relevant data validation, cleaning, and aggregation with minimal content loss. This includes data sampling, feature creation (creating new features that capture the main information of the data more effectively than the original features), and feature selection (enriching content) to add extra context for the data, as it is intended to assist the model.
5. Data Annotation: Last year, the nation released seven annotation bases located in cities like Hefei, Changsha, and Haikou. In Suqian City, we collaborated with Jiangsu Zhongwu Big Data Development Group to establish a Data Annotation Evaluation Center. We have conducted foundational work to unify the quality standard dimensions and scenarios for data annotation, and also need to manage the annotation process effectively.
6. Model Validation and Evaluation: This is not only a comprehensive review of model performance but also a critical safeguard to ensure the model operates stably and reliably in real-world scenarios. Therefore, all related work must be done rigorously and meticulously, covering aspects from the selection of validation methods and the formulation of evaluation standards, to the collection and processing of validation data, and finally to the interpretation and application of evaluation results, ensuring accurate assessment and effective validation of model performance.

Industry Outlook
Q5: Currently, the introduction of multiple policies is promoting the marketization of data elements. How do you think emerging technologies (such as blockchain and privacy-preserving computation) will influence the construction of high-quality datasets? Does your team have any forward-looking plans or innovative initiatives in this regard?
A5: Wang Feng
—— Our team has undertaken some innovative work in the field of data spaces.
The nation is actively advancing the construction of data infrastructure. Among the initiatives, blockchain and privacy-preserving computation, as two core technical routes, are playing a critical role. Additionally, related construction work involving data fields, data components, data networking, and trusted data spaces is also progressing simultaneously.
Especially concerning data spaces, there are already published cases of advancements in enterprise, industry, and city-level initiatives, along with explorations into personal and cross-border data spaces. Relying on data spaces, not only will blockchain and privacy computing affect high-quality dataset construction, but the current infrastructure construction will also have a profound impact on the development of the entire data market. This includes future improvements in data circulation efficiency, the creation of scenario-level applications and business models, which will heavily depend on the infrastructure. Our team has carried out some innovative work in this area:
1. Publishing a White Paper and Building a Trusted Quality Data Space: In November of this year, we published the Trusted Quality Data Space White Paper. We are currently building a Trusted Quality Data Space and simultaneously exploring new models for digital certification.

2. Proposing an Architecture and Building New Quality Infrastructure: With the core goal of constructing a high-level, new type of quality infrastructure, we have proposed a Quality Data Service Network Architecture. Leveraging this architecture, we are exploring new approaches for digital certification. Using technologies like blockchain, privacy computing, and trusted data spaces, we aim to build new quality infrastructure. This enables quality certification data to be "usable while invisible, usable without leaving the domain, and controllable and accountable." We are developing digital certification business specifications and identifiers covering the entire process, and achieving intelligent judgment of certification results through the modeling of the certification process.

From an industry development perspective, the digitalization of quality certification requires support from high-level quality certification infrastructure. The trustworthy circulation, secure sharing, and efficient utilization of quality data are key bottlenecks and infrastructure requirements. Existing quality data suffers from issues such as fragmentation and isolation, inconsistent standards, and insufficient trustworthiness. This leads to low work efficiency, poor cross-domain coordination, and difficulty in expanding digital scenarios. Current methods relying on manual factory inspections and some digital tools make it hard to achieve real-time certification or provide in-depth quality diagnostic services. This hinders the development of industries to higher levels and fails to meet the certification needs of enterprises as they evolve towards "unmanned factories." Once the Quality Data Service Network is established, it will bring multiple improvements: it will enable real-time certification evaluation; it will significantly enhance the effectiveness of certification work, thereby improving the validity of high-quality dataset evaluations; and it will provide public services for the industry, meeting the demand for quality data, for example, in scenarios like supporting the quality improvement of small and medium-sized enterprises.
Q6: What advice would you like to share with young people about to enter the data field?
A6: Wang Feng
—— I suggest that young people keep track of technological developments and policy trends in a timely manner, deeply engage in industry scenarios, pay attention to the "AI+" trend, and build their own industry networks.
1. Continuously Track Technological Development: The data industry encompasses a rich variety of technical routes, such as blockchain and privacy computing, which are key technologies. Take data spaces, for example; they include five types: personal, cross-border, enterprise, industry, and city. Personal data spaces involve issues like privacy protection and data sovereignty; cross-border data spaces need to address challenges like data cross-border flow rules and security protection; enterprise, industry, and city data spaces each have their own construction focuses and future scenarios. Young people must stay at the forefront of technology, deeply understand the principles, application scenarios, and development trends of these technologies, and build a solid foundation for their careers.
2. Pay Close Attention to Policy Trends: China is the first country to recognize data as a factor of production, and its policies are highly innovative and iterate quickly. Recently, a policy document on data property rights began soliciting public comments. The new measures and trends within it indicate the direction of industrial development. Young people should closely monitor policy changes, accurately grasp the policy direction, so they can align with the industry's development and seize opportunities brought by policy dividends.
3. Root Themselves in Industrial Practice: Data elements cannot exist independently of industry. Young people should immerse themselves in the industries corresponding to their professional fields and, through practice, combine data elements to drive industrial development. For example, consider how to achieve the industrialization of data and the digitalization of industry, as well as the transformation of data into resources, resources into assets, and assets into capital. Developing data elements in isolation from industry is like a tree without roots or water without a source. Only through industrial practice can data elements realize their true value.
4. Deeply Understand Industry Scenarios: Scenarios are the bridge connecting technology with industry, and linking R&D with the market. They are crucial for promoting the integrated development of technological and industrial innovation. Document No. 37 issued by the General Office of the State Council emphasizes accelerating the cultivation and opening of scenarios to promote the large-scale application of new scenarios. In the data element industry, young people need a profound understanding of industry scenarios because only then can they fully leverage the power of data elements and avoid disappointment caused by insufficient scenario comprehension, even in a seemingly hot field like the data industry.
5. Integrate with the Development of Artificial Intelligence: Since the beginning of this year, AI has developed rapidly, and "AI+" has become a common consensus. The foundational support for AI includes algorithms, data, and computing power. Currently, computing power and algorithms are not the main shortcomings. High-quality datasets are the key to improving the development level of the AI industry; they can be considered the "ceiling" for AI. Young people should focus on how to enhance the development level of the AI industry by creating high-quality datasets, and consider what work they can undertake in the wave of "AI+".
6. Actively Expand Networks and Build an Ecosystem: The development of the data industry requires collaboration from all parties. Young people should make more friends within the data industry, listen to their understanding and insights about the market. Through communication, not only can they broaden their horizons, but they can also build a strong ecosystem to jointly advance the development of the data industry.

